

Authors: Abisola Ojikutu and David Goldberg
This post was written by actual humans.
Today Generative AI is the hottest topic on the block: hundreds of startups are launched in the space every day. As investors watching Generative AI closely, we wanted to dig deeply into the following question:
What does the generative AI landscape look like, and how should we be evaluating opportunities?
It’s a seemingly simple query. But as you’ll see below, there’s much to unpack in this new and rapidly expanding landscape. At Alpaca VC, we conduct regular deep dives we call Field Studies into areas where we see opportunities. As part of these studies, we speak with thought leaders, experts, investors, and entrepreneurs willing to share their perspectives. After weeks of conducting this Field Study research on the Generative AI space, we’re excited to share this post to provide a high-level overview of the space and our initial thinking about evaluating emerging startups.
We are, of course, still in the earliest days of AI and its applications, and this is a true, novel technology. As such, we view this initial look as a jumping-off point for deeper dives later this year.
Part I: Generative AI Trends
Generative AI — Why All the Buzz?
ChatGPT, the generative AI app from OpenAI, has captured the attention of the everyday person, from students in high school or college to knowledge workers grinding through a hard day of work to creatives looking for inspiration. The whole world (not just techies deep in Silicon Valley) seems to be buzzing with all things Generative AI, all thanks to ChatGPT, which, according to UBS Analysts is the fastest-growing app in the history of the Internet. It is estimated to have reached 100M users by January 2023 — just two months after its Nov 2022 release. To put this into perspective, TikTok had 35.7M U.S. users in 2019 after being released in Aug 2018.
ChatGPT relies on a Large Language Model (LLM) GPT 3.5 to produce what seems to be magic: well-strung together, coherent responses to all sorts of questions. In a recent white paper, OpenAI stated that with access to an LLM about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When software and tooling are incorporated on top of the LLMs, this share increases to 47-56%.
In short, Generative AI will have a significant impact on the way most of us do work.
Anecdotally, it’s easy to see evidence of this in the study rooms and classrooms of the business school campus where much of the research for this study took place: it’s common to spot students with ChatGPT open as a tab alongside productivity staples such as Google Search, Word or Excel. We also see evidence of this in products like GitHub Copilot, a text-to-code AI system, where survey results showed 88% of respondents felt more productive when using the system and 74% felt they were able to focus on more satisfying work.
With the release of these LLMs, startups are launching left, right, and center to build products on top of these models and vie for as much VC investment and attention as possible in the midst of this economic downturn. Per Pitchbook, there has been a 22.5% compound annual growth in the number of companies founded in the Generative AI space between 2013 to 2022. Yet evaluating these startups amid the rapid pace of development presents an interesting challenge. First, let’s take a step back to understand capital flows.
Follow the Money
Enterprise Adoption and Spending
AI has been around for quite some time, but the release of ChatGPT, among others, has made it more visible than ever. The level of investment in AI by corporations has increased alongside its rising adoption.
Per Mckinsey’s Global Survey on AI 2022, AI adoption has more than doubled.
In 2017, 20% of survey respondents reported adopting AI in at least one business area, while in 2022 (prior to the release of ChatGPT in Nov 2022) that figure stood at 50%.
When asked about company budget allocations to AI investments, 63% of respondents expect their organization’s investment to increase over the next three years.
Unlike past Big Data technologies where the potential to use data to gain insights and make decisions was not fully realized due to the lack of organizational talent and expertise to manage and analyze datasets (i.e. the Big Data Redux), Generative AI could be easier for companies to leverage given the heavy lifting in LLMs completed OpenAI and others. Pitchbook reports that Generative-relevant use cases already present a significant enterprise opportunity, estimated to reach $42.6 billion in 2023 and growing at a 32.0% CAGR to reach $98.1 billion by 2026 — even without accounting for generative AI’s expansion beyond current use cases to consumers and new user personas outside of customer service and sales process automations.
VC Funding
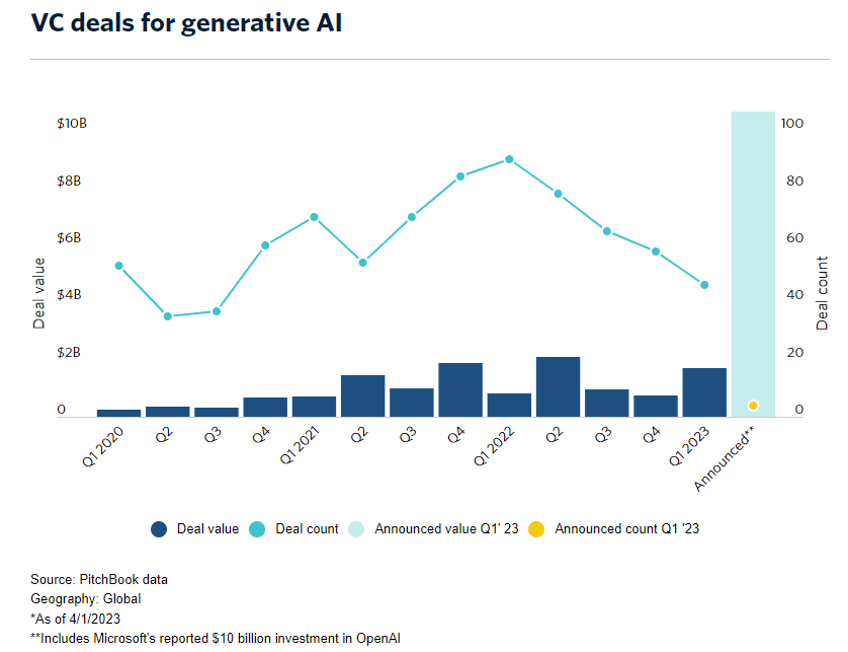
As companies increase their investment in the AI space, so does the Venture Capital world.
Per Pitchbook, in 2022 globally, Generative AI received $4.7B of funding across 375 deals.
In Q1 2023, it received $1.7B across 46 deals.
That means 2023 is already on track to outpace 2022 funding despite slowdowns in the economy. It feels like this number gets updated (a.k.a. increased by a LOT) every week.
Innovation at Breakneck Speeds
OpenAI released ChatGPT in Nov 2022 and the world has not been the same since. It then released GPT-4, its new and improved large multimodal model in March 2023. GPT-5 is expected by the end of the year. In reaction to competition from OpenAI’s ChatGPT, Google released Bard in March 2023 to lackluster reviews; however, it is safe to assume we can expect more from Google over the next few months.
Microsoft announced AI Copilot for Microsoft 365, while Meta (not to be left behind) noted recently that AI-powered tools to help with creating ads can be expected soon. In April 2023, Meta released its Segment Anything Model (SAM) that can “cut out” any object in any image with one click. Baidu, a Chinese search giant, released its own language model Ernie (Enhanced Representation through Knowledge Integration). Suffice it to say, a lot has been happening in this space.
GPT-4 and the Move Towards Multi-Modality
One of the biggest events in the Generative AI space has been the release of GPT-4, which is said to be better than GPT 3.5 on many dimensions, from being “more creative and collaborative” to reasoning and better language comprehension. Most notably, its ability to accept images as inputs is a game changer as this capability broadens use cases and the types of applications that can be built on top of the model. Past models such as GPT 3.5 have been text-only, but with the release of GPT-4, a multi-modal model, we are increasingly seeing a shift towards models that can accept multiple types of inputs (image, video, text, audio).
Multi-modality is on the rise and is here to stay. The ability for models to interpret and generate responses based on multiple modalities leads to more accurate and context-relevant outputs and ultimately unlocks a world of possibilities for startups building on the app layer. We are already beginning to see companies such as Khan Academy leverage multi-modal capability by using GPT-4 to power its AI assistant Khanmigo, a virtual tutor for students and classroom assistant for teachers.
GPT-4 marked a transition in the behavior of OpenAI from a non-profit research company to a Big Tech company. It did not reveal anything about how GPT-4 was built, no details on training techniques or dates. This is a far departure from how it communicated with the public during its last releases. What is known is that Reinforcement Learning from Human Feedback (RLHF) similar to GPT 3.5 was used. Like past models, there are still many limitations such as hallucinations, social biases, lack of knowledge of events more recently than September 2021, incorrect facts, and an inability for users to connect facts to authoritative sources.
Part II: Let’s Get Technical
What is an LLM, Really?
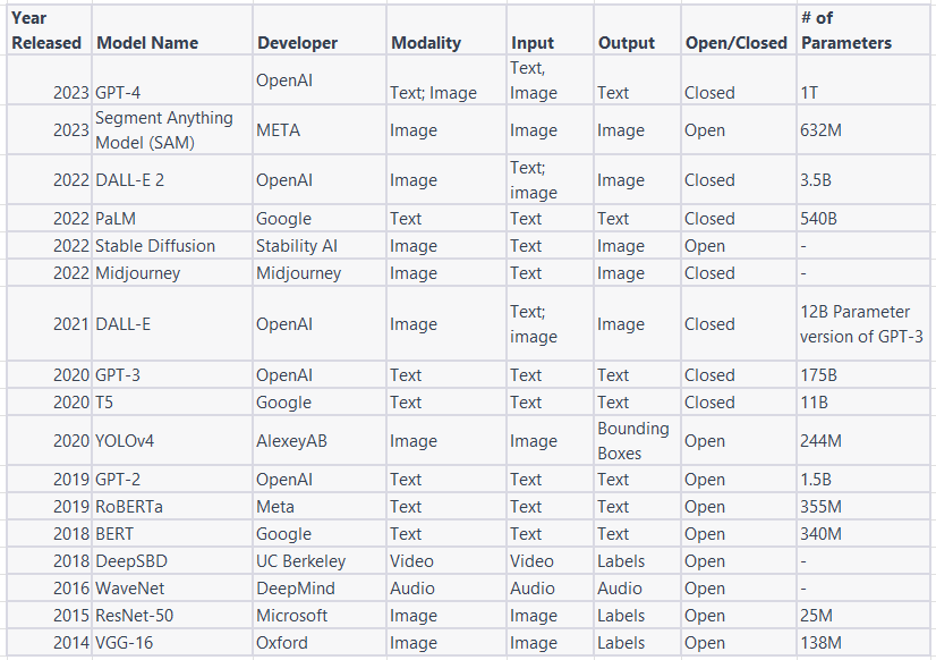
A Large Language Model (LLM) is a deep learning algorithm that can recognize, summarize, translate, and generate content based on the knowledge gained from other data sets. Deep learning algorithms have been made possible by the vast amount of digital data available on the web, by advances in computer power, and by the development of GPUs (Graphic Processing Units). Some models are open, meaning the source code is available to all or some members of the public while others are closed proprietary source code inaccessible to the public. Some models are multi-modal, meaning they work with more than one content/data format (i.e. text, image, video, etc.), while others are mono-modal. See table below for breakdowns of popular models and their classification by open/close and modality.
When we asked experts whether or not the market will tip in favor of big players such as OpenAI, the Alpaca team consistently heard the same sentiment: “It is hard to know if others will catch up, but OpenAI has a massive lead.”
The thought is that OpenAI will remain the biggest and most dominant player given its lead in Natural Language Processing (NLP) and smaller players will arise with a focus on highly specialized models for specific use cases. The thinking is that this phenomenon will continue to play out across modalities from text to image and video and beyond. Similar to how companies today use a combination of AWS, Azure, and Google Cloud products in their tech stacks as a form of risk mitigation and diversification, we believe we will see startups move towards leveraging a combination of models, from horizontal, broad-based models to those that are more vertical-specific. We might also see players like OpenAI begin to release different tiers of their models, with varying levels of quality and, as a result, varying costs.
Open vs. Closed LLMs
LLMs are typically based on transformer architecture and trained using reinforcement learning which is applicable for both open and closed-source models and across modalities. All LLMs (open or closed) are capital-intensive, taking up a lot of time and money to build. Without being a Big Tech company or a very well-funded startup, these models are almost impossible to build.
Open LLMs can have many benefits for startups as they allow teams to leverage already existing models and code, accelerating a developer’s pace of experimentation without the need for deep experience in LLMs and Machine Learning. This makes it flexible and cost-efficient for startups to test, experiment, and launch AI products quickly. However, “hallucinations” resulting in incorrect facts and data may become problematic, especially for startups launching in specific high-accuracy verticals such as healthcare and banking. Fact-checking needs to take place, especially in the context of vertical applications in sensitive industries.
Closed, proprietary LLMs, on the other hand, are often touted to have improved privacy, increased accuracy due to fine-tuning on specific data sets and tasks, and better performance (because these models can be optimized for specific hardware). However, with closed-source LLMs, startups are beholden to the LLM developer. From a cost structure perspective, API costs can eat into startup margins and negatively impact business model sustainability. There is also the risk that, for some reason or another, the LLM a startup is built on top of ceases to exist or is no longer made available to developers due to regulatory crackdowns or other factors outside their control.
There is a balance that needs to be struck between the speed and innovation that open models allow and the privacy and accuracy that closed proprietary models can provide. Are switching costs significant between open and closed models and will there be a dominant player in the LLM game? When switching between models, integration, and compatibility are key factors to consider — it may be time-consuming and expensive for a startup to adjust its existing infrastructure, software, and apps to work with a new model.
What are the Layers of the AI Stack?
The foundational model layer of the AI stack has garnered a lot of public spotlight in the past year thanks to OpenAI; however, there are multiple layers in the AI stack that come together for startups to launch and thrive in this space.
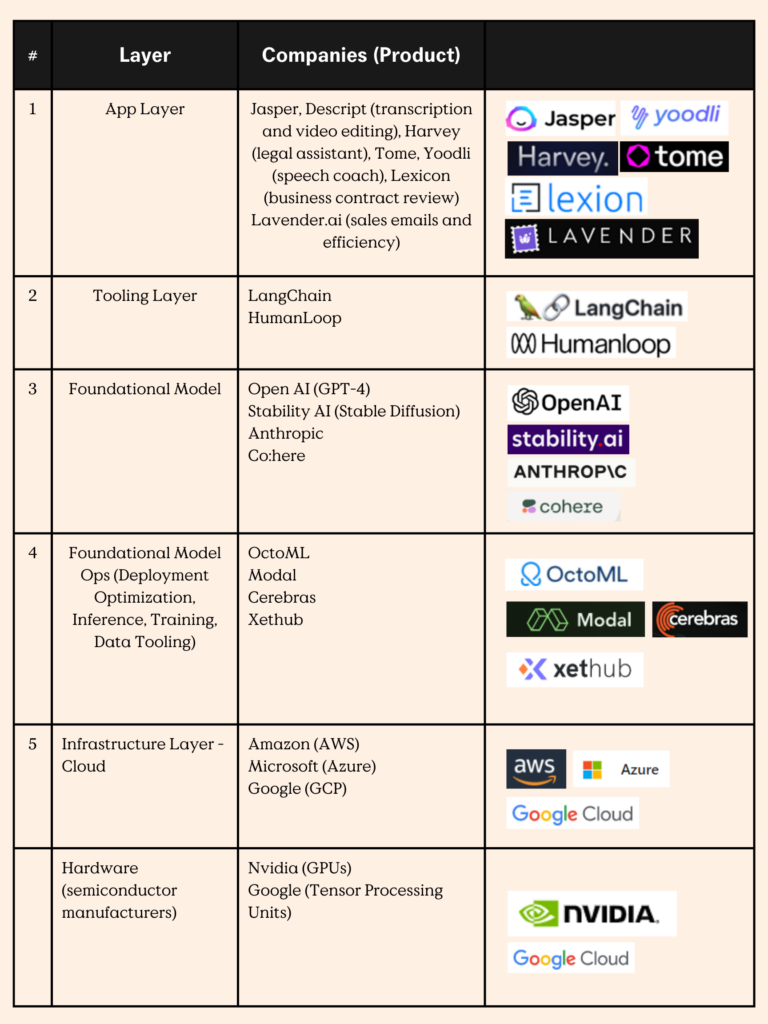
(1) Application Layer: First we have the application layer, the focus of the latter part of this post. This is the layer that most everyday consumers will interact with. There has been an explosion of offerings in this area, with companies such as Jasper, Runway, Harvey, and Tome coming into the picture. Margins at the application layer could be as high as 90% and on the low end 50–60%, per experts. However, a lot is yet to be seen as to how these margins shake out over time especially considering the high compute costs startups face.
(2) Tooling Layer: Second, we then have the tooling layer, which enables developers to build foundational model applications more quickly. Examples of startups operating in this layer are LangChain and HumanLoop. In our conversations with experts and builders, this layer is especially sticky, as it is embedded in the engineers’ and designers’ workflow. Switching costs are high, and this layer is critical to making the foundation model more accessible and user-friendly to a wider range of developers.
(3) Foundational Model Layer: The third layer is the foundation model layer, which includes open-source and closed-source large language models (LLMs) from OpenAI’s GTP 4 to c0; here and Google’s PaLM.
(4) Foundational Model Ops Layer: The foundation model ops layer allows developers to optimize, train and run their models more efficiently. OctoML and Modal are examples of startups in this layer.
(5) Infrastructure Layer: Lastly we have the fifth layer, the cloud and hardware infrastructure that facilitates the training of LLM in the first place. Providers in the infrastructure layer are said to be the true winners at this stage in the Generative AI revolution, given the amount of computing power needed to train LLMs. Cloud providers such as AWS, Azure, and semiconductor manufacturer Nvidia are cashing in. As an example, Nvidia dominates 95% of the GPU market required by the AI & ML industry. Today it is estimated that 10–20% of the total revenue in Generative AI goes to cloud providers.
Zooming In on the Application Layer
The application layer development is typically quick and less costly, however:
- Product differentiation is hard
- Retention is difficult
- Margins can be low
- Network effects are not always obvious
Taking a step back, differentiation must be made between Generative Native Apps and Generative Enhanced products/companies.
Generative Native vs. Generative Enhanced Apps
Generative Native Apps are a new category entirely unlike the SaaS products we have historically been used to. These apps are built directly on top of an LLM and generate content without needing explicit instructions other than simple “prompts” — examples include Jasper, Harvey, RunwayML, fireflies.ai.
These apps typically manifest as horizontal applications (more on this later). Generative Native Apps can benefit from low cost to build. When startups rely on APIs to external LLMs, they don’t at the onset need to invest large amounts of capital to build their own models. This allows a faster time to market, similar to what we saw with cloud-native companies that didn’t need to spend the time and capital to build on-premise infrastructure. Additionally, similar to cloud computing, Generative Native companies have the ability to dial up and down their use of LLMs as they adapt to workload and demand variability. That said, to be a true AI startup with longevity, founders will need to build some of their own models as opposed to solely relying on APIs.
We can think of Generative Enhanced products as already existing SaaS companies such as Notion and Canva who are beginning to integrate AI or LLM features into their existing products. In our conversations with AI experts and professors in academia, the general thinking is: if a company does not have some sort of LLM integrated in their product within the next two to three years, they are essentially doomed. We have seen companies like Notion release Notion AI for brainstorming, summarization, and first drafts. Canva released Magic Write. The key differentiator between a Generative Native vs. Generative Enhanced app is that the core and key value prop of the generative enhanced app is not predicated on Generative AI technology or use of LLMs — these are simply add-on features. The disadvantage with these apps is that integrating Generative AI into existing workflows can be challenging, increase development costs and time, and potentially result in compatibility issues that may or may not affect the user experience. As we know, UX and ease of integration are key to customer engagement and stickiness.
Generative Native Apps — Vertical Applications
The universe of Generative Native Apps can be cut in a multitude of ways, by area of vertical application, by modality (text, image, video, etc.), or by form such as desktop app, mobile apps, plug-ins, and Chrome extensions. Here we will be focusing on the vertical cut. These are applications that serve a specific task or problem typical in one industry or line of work (Banking, Accounting, Sales & Marketing, Legal, Productivity, etc.).
Harvey, the legal tool to help increase efficiency among lawyers, is an example of a vertical application in the legal section. It recently won OpenAI’s startup fund competition in Nov 2022 and received $5M in funding. Vertical applications tackling a specific problem have the benefit of being able to focus on fine-tuning models based on a focused data set (i.e. patient data for a healthcare use case). For startups operating in a specific vertical to succeed they must find a single problem/use case to solve and do it so well with easy and sample UX that users can no longer imagine their lives without it — once they start, they are hooked and can’t stop. Working hand in hand with specific companies to codesign the product can be the key to achieving great UX and proprietary data insights.
Part III: Assessing Ideas and Opportunities
What Frameworks Should We Use to Assess Generative AI Startups?
Startups are launching and building fast, but it is difficult to know for certain who is actually building Generative AI Native products as opposed to features in a traditional SaaS product. More importantly, there is a risk of a lack of product differentiation. Founders are building products using similar, if not the same, models trained on the same data sets with the same architectures. With so many startups now building for some of the same use cases (e.g. marketing, copywriting, email writing), it can be hard to ascertain who has a unique edge or moat, and what solutions are cost-effective and poised to succeed. A unique edge results in value creation for the customer derived from lower costs or increased productivity and performance or increased revenue. When evaluating whether a unique edge is present, we look for one or all of the following:
(1) Proprietary Data:
To differentiate themselves in the age of ML, startups require proprietary new data sets derived from user interaction and feedback from the use of their product. This algorithm moat or data access moat occurs when the startup fine tunes and improves the baseline LLM using domain-specific data or customer data (e.g. patient data, legal data) that is inaccessible to others. Proprietary data plus AI adds value to the end user in a way that keeps them coming back. However, with gaining this type of data advantage comes the need for access to talent with deep technical expertise, high costs, high capital requirements and sometimes regulatory friction. A startup must balance data acquisition and training costs and incremental data value, making sure the data they are acquiring, cleaning, and labeling results in a dramatically better and stickier product. We are seeing startups raise large seed rounds due to the high cost of talent and computing required to build a proprietary data moat. As an example, Jasper raised a $140.56M Series A round in Oct 2022.
The key question here is, how much data is enough data and what is the incremental value add?
(2) User Experience:
User experience can make or break a product. We have seen cases where UX has driven brand loyalty (case in point: Apple products). Even the widespread use of Generative AI is largely driven by the easy-to-use ChatGPT user interface that provides a seamless experience for anyone wanting to use OpenAI’s LLM to answer questions. In the age of Generative AI, unlike before, the right design choices include considerations about the type and format of inputs (i.e. prompts) and the type, format, and quality of outputs that users want in their specific context.
The key questions here are:
Are the prompts the user naturally inputs understood and interpreted in a way that generates outputs that are expected and helpful to the user?
Does the product integrate easily into user workflows from and input and output perspective?
(3) First Mover’s Advantage:
Being a first mover and dominating the go-to-market strategy such that the startup has strong brand recognition and a large installed user base could be an advantage. This type of advantage can discourage others from launching or result in a situation where the gap is so wide that competitors are unlikely to catch up. It should be noted: the first mover’s advantage is hard to keep up given the increase in accessibility to models, data, and increases in specialized talent pools thanks to recent tech layoffs. The key questions here are:
How far of a lead is there and can it be maintained?
What are others building in this space and how easy is it for them to catch up and replicate?
(4) Ecosystem Advantage:
An interesting moat to consider is the startup’s ability to seamlessly work together with already established software their customers use in their current workflow or the ability to create an ecosystem suite of products that solves multiple problems for their users. Deep integration into the day-to-day tasks of users is key. As an example, plugins into Chrome, Zoom, and Microsoft products are examples of seamless integrations. A startup that develops a comprehensive ecosystem with a wide range of integrations, plugins, or content while leveraging data and input from users is hard to replicate.
The key questions here are:
Does this startup have the potential to create its own ecosystem with multiple product offerings?
Is the product operating in a way that easily works with existing products used by customers?
Summary and Concluding Thoughts
The future of the Generative AI space is exciting. As we continue to investigate this space further, we will explore the following questions:
- What will the world will look like two to five years from now?
- How will this space revolutionize the way we work, play, and live?
- What is the right business model in the age of generative AI (per usage, subscription, hybrid, or something else)? What are the average margins at each layer of the stack?
- How will business models be impacted by upcoming trends in data rights and regulations?
- What is the best data strategy for startups to pursue? How should startups be thinking about data management and governance?
- How will generative AI shape the future of crypto and web3?
- Do we see some startups potentially replacing traditional software stacks such as Oracle, SAP, or Salesforce?
We look forward to updating you in the next installment of this Field Study series.
For more deep dives into our current areas of interest, visit Alpaca Field Studies.
Author’s Acknowledgements:
Our author Abi and the Alpaca team would like to thank the generous individuals who spoke with us and shared their take on the Generative AI space, including Andy Wu, Harvard Business School Strategy & Technology professor; Ben Parr, AI Expert and Co-Founder and President Octane AI; Henele Adams, Ex-Google Engineer, and Entrepreneur; Kyle Dolce, Glasswing Ventures; Miaomiao Zhang Harvard Business School Ph.D. Candidate and Seth Schuler, Strategy Expert and Entrepreneur.
Disclaimer: Alpaca VC Investment Management LLC is a registered investment adviser with the U.S. Securities and Exchange Commission. Information presented is for informational purposes only and does not intend to make an offer or solicitation for the sale or purchase of any securities. Alpaca VC’s website and its associated links offer news, commentary, and generalized research, not personalized investment advice. Nothing on this website should be interpreted to state or imply that past performance is an indication of future performance. All investments involve risk and unless otherwise stated, are not guaranteed. Be sure to consult with a tax professional before implementing any investment strategy. Past performance is not indicative of future results. Statements may include statements made by Alpaca VC portfolio company executives. The portfolio company executive has not received compensation for the above statement and this statement is solely his opinion and representative of his experience with Alpaca VC. Other portfolio company executives may not necessarily share the same view. An executive in an Alpaca VC portfolio company may have an incentive to make a statement that portrays Alpaca VC in a positive light as a result of the executive’s ongoing relationship with Alpaca VC and any influence that Alpaca VC may have or had over the governance of the portfolio company and the compensation of its executives. It should not be assumed that Alpaca VC’s investment in the referenced portfolio company has been or will ultimately be profitable.
COPYRIGHT © 2025 ALPACA VC INVESTMENT MANAGEMENT LLC – ALL RIGHTS RESERVED. All logo rights reserved to their respective companies.